1. Bayes' rule이란?
"Bayes' rule in a rigorous method for interpreting evidence in the context of previous experience or knowledge."
Bayes' Rule는 이전 경험이나 지식을 바탕으로 증거를 해석하는 엄격한 방법론이다.
Prior를 기반으로 새로운 Evidence가 주어졌을 때 Posterior를 업데이트 하는 방식이라는 뜻이다.
1.1. Bayes' rule의 의미
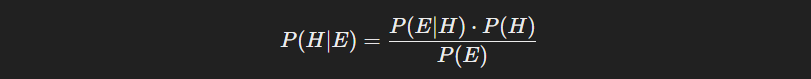
- 사후 확률(posterior probability)로 증거 E가 주어졌을 때 가설 H가 참일 확률
- P(H): 사전 확률(prior probability)로 가설 H가 증거 없이 참일 확률
- P(E∣H 가능도(likelihood)로 가설 가 참일 때 증거 가 일어날 확률
- 증거의 확률(evidence probability)로 증거 가 발생할 전체적인 확률이다. 가설이 참일 때와 거짓일 때 모두를 포함한다.
이를 통해 우리는 기존의 믿음(사전 확률)을 보완하고 새로운 데이터를 반영해 가설이 사실일 가능성(사후 확률)을 업데이트할 수 있다.
1.2. 예시: 90%의 마약 테스트기

테스트가 양성이더라도 실제 마약을 복용했을 가능성은 75%이다.
- 오진률: 양성 반응이 나와도 실제로 마약을 복용하지 않은 경우 양성 판정을 받을 확률이 상대적으로 높으면, 사후 확률은 낮아진다. 즉, 테스트 결과만으로 신뢰할 수 없다는 점을 강조한다.
- 사전 확률 (Prior): 특정 인구 집단에서 마약을 복용할 가능성이 낮으면 사후 확률은 낮아진다. .
- 가능도 (Likelihood): likelihood가 커질수록 가설에 대한 신뢰도가 커진다. 그러나 이는 절대적인 건 아니며 prior의 비율이 적다면 신뢰도도 줄어들 수 있다.
- 증거 확률 (Evidence Probability) : 증거(양성 반응)가 흔하게 발생하면, 정규화 상수 P(E가 커져 사후 확률은 낮아진다.
- 종합 판단: 테스트 결과만이 아니라 사전 확률과 가능도를 함께 고려해야 가설에 대한 신뢰도를 정확히 평가할 수 있다.
2. 인공지능에서 활용
2.1. 확률 분포와 분류
인공지능에서 다루는 데이터는 일반적으로 확률 분포를 기반으로 모델링된다. 예를 들어, 고양이와 강아지의 무게를 통해 이 두 클래스(고양이, 강아지)를 구분하는 문제를 생각해보자.
- 예시: 고양이와 강아지
- 고양이의 무게 분포: 평균 4kg, 분산이 적당하여 4kg일 때 확률이 0.8
- 강아지의 무게 분포: 평균 4kg, 분산이 적당하여 4kg일 때 확률이 0.4
이 경우, 무게가 4kg인 경우:
- 고양이일 확률: 0.8
- 강아지일 확률: 0.4
인공지능에서 다루는 대상은 확률 분포의 형태로, 특정 값이 아닌 특정 위치에 얼마나 분포해 있는지를 나타낸다.
예를 들어, "4kg이면 고양이다"라고 단정짓는 것은 잘못된 접근이다. 실제로는 고양이 분포에서의 확률이 0.8, 강아지 분포에서의 확률이 0.4이므로, 가장 높은 가능성을 가진 고양이 분포가 정답임을 나타낸다.
2.2. Bayes' rule의 활용

Bayes' rule에서, likelihood와 prior의 값이 크다면 해당 가설에 대한 신뢰도가 커진다. likelihood와 prior만 곱해주고 각 클래스 간의 분포를 고려하는 것이 중요하다.
* Evidence를 생략하는 이유 *
evidence(증거)는 클래스 간의 상대적 차이를 중요시하는 데에 초점을 두므로, 꼭 확률을 1로 맞출 필요는 없다. 여기서 1은 각 클래스의 확률의 총합을 의미하며, P(E)에 해당하는 E는 데이터 값이므로 계산할 필요는 없다.
2.3. Likelihood의 역할
Likelihood는 사건 B가 발생했을 때, 분포 A에서의 B의 확률을 나타낸다. 이 값을 이용해 prior와 곱함으로써, 가장 적절한 클래스와 해당 분포를 찾아낼 수 있다.
2.4. 최대 우도 추정법 (MLE)
MLE(Maximum Likelihood Estimation)는 주어진 데이터로부터 모델의 파라미터를 추정하는 방법으로, likelihood를 최대화하는 파라미터를 찾는다.
이는 주어진 데이터가 관찰될 확률이 최대가 되는 파라미터를 찾는 것을 의미하며, 각 클래스에 대해 가장 적합한 값을 도출하는 데 중요한 역할을 한다.